Multi-Platform Job Scraper & Data Pipeline

Overview Proyek
Job Vacancies Analytics adalah platform scraping otomatis yang mengumpulkan data lowongan kerja dari enam job platform Australia secara serentak — Jora, Seek, Indeed, CareerOne, Adzuna, dan Workforce — lalu memprosesnya menjadi data yang bersih, terstruktur, dan siap diimport ke CRM.
Platform ini dibangun untuk kebutuhan operasional Interlace Studies dalam memantau demand employer di pasar kerja Australia secara real-time. Dengan 178 scraping jobs yang sudah dijalankan dan 18.938 total records terkumpul, sistem ini menjadi sumber data utama untuk memahami siapa employer yang aktif merekrut, di bidang apa, dan di state mana.
Ide Bisnis
Untuk bisa menghubungkan kandidat dengan employer yang tepat, Interlace Studies perlu tahu dua hal: occupation apa yang sedang banyak dicari, dan siapa employer konkret yang sedang membuka lowongan tersebut.
Data shortage dari pemerintah memberikan gambaran makro — tapi tidak memberikan nama perusahaan, nomor telepon employer, atau informasi kontak yang bisa langsung di-follow up oleh tim business development. Job platform seperti Seek dan Jora punya data itu, tapi tidak ada cara otomatis untuk mengumpulkannya dalam skala besar dan mengubahnya menjadi leads yang actionable di CRM.
Job Vacancies Analytics mengisi gap itu. Setiap scraping job mengumpulkan lowongan berdasarkan keyword occupation dan filter state tertentu, mengekstrak detail employer dari setiap listing, lalu memformat datanya menjadi format yang langsung bisa diimport ke GoHighLevel (GHL) sebagai contacts atau leads.
Hasilnya: tim Interlace bisa melakukan outreach ke employer yang sedang aktif merekrut untuk occupation shortage — bukan cold outreach ke database random, tapi targeted outreach berdasarkan sinyal hiring yang nyata dan terkini.
How We Executing
Multi-Platform Scraping Engine
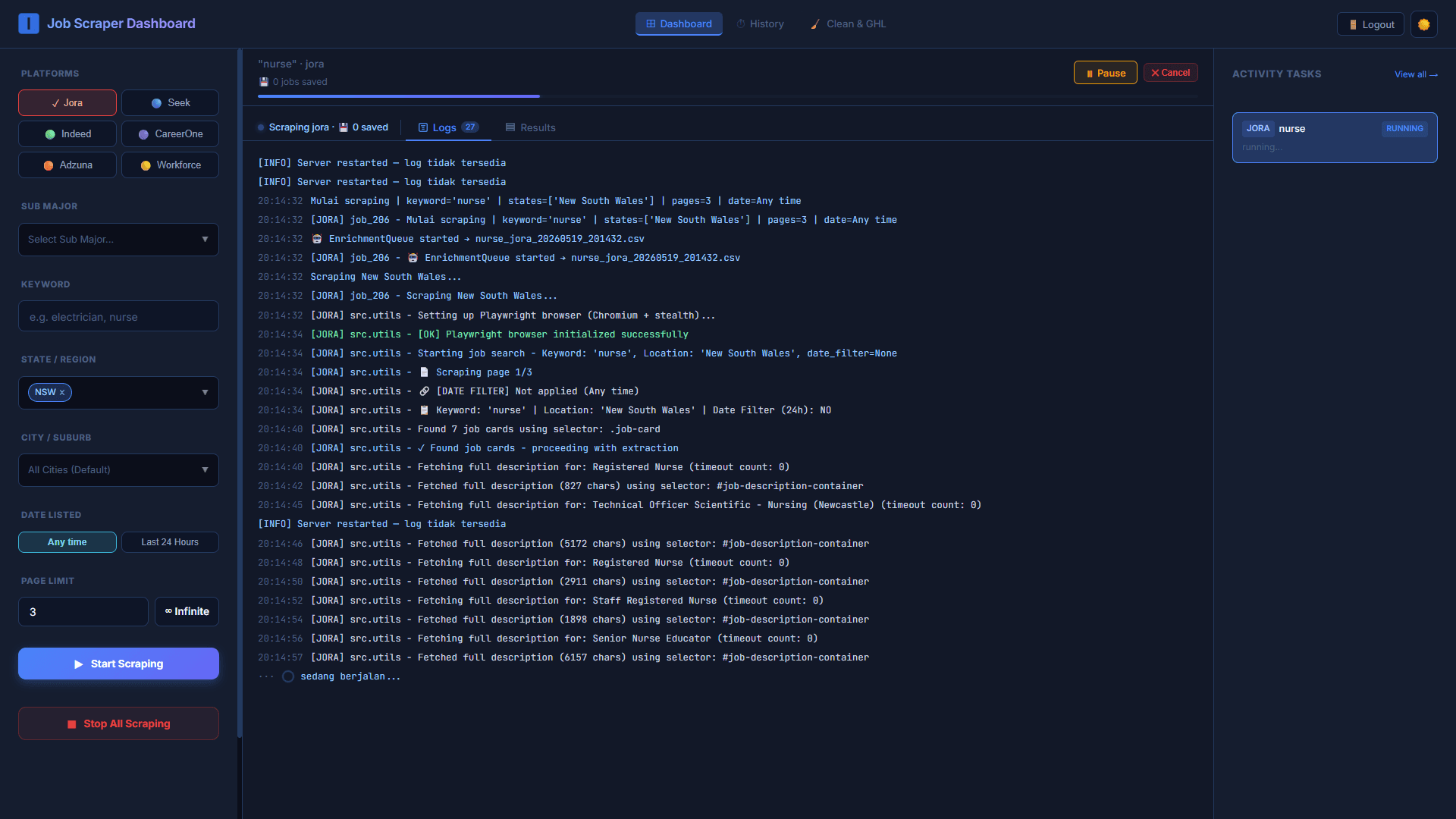
Dashboard utama memungkinkan user memilih satu atau lebih platform target dari enam opsi yang tersedia. Setiap platform punya behavior yang berbeda — struktur HTML, pagination, lazy loading, bot detection — sehingga scraper untuk masing-masing dibangun dan dikalibrasi secara terpisah.
Scraping dijalankan menggunakan Playwright dengan Chromium stealth mode — browser automation yang dirancang untuk menghindari deteksi bot. Log real-time menampilkan setiap langkah proses: inisialisasi browser, pencarian keyword, navigasi halaman, ekstraksi job card, hingga fetching full job description per listing.
Parameter scraping yang bisa dikonfigurasi per job:
Platform
— pilih satu atau kombinasi dari Jora, Seek, Indeed, CareerOne, Adzuna, Workforce
Keyword
— occupation name (misalnya "nurse", "Plasterer Wall and Ceiling Sponsorship", "painter sponsorship")
State/Region
— bisa spesifik ke NSW, VIC, QLD, dan lainnya
City/Suburb
— filter lebih granular atau default ke semua kota
Date Listed
— Any time atau Last 24 Hours untuk data fresh
Page Limit
— batasi jumlah halaman yang di-scrape, atau set ke Infinite
Real-Time Log & Monitoring
Saat scraping berjalan, panel Logs menampilkan output langsung — mulai dari "Mulai scraping | keyword='nurse' | states=['New South Wales']" hingga setiap job card yang ditemukan dan setiap full description yang berhasil di-fetch beserta jumlah karakternya. Ini memudahkan debugging ketika ada timeout atau selector yang gagal.
Activity Tasks di panel kanan menampilkan semua job yang sedang running secara bersamaan — memungkinkan beberapa scraping job berjalan paralel tanpa saling mengganggu.
History & Job Management
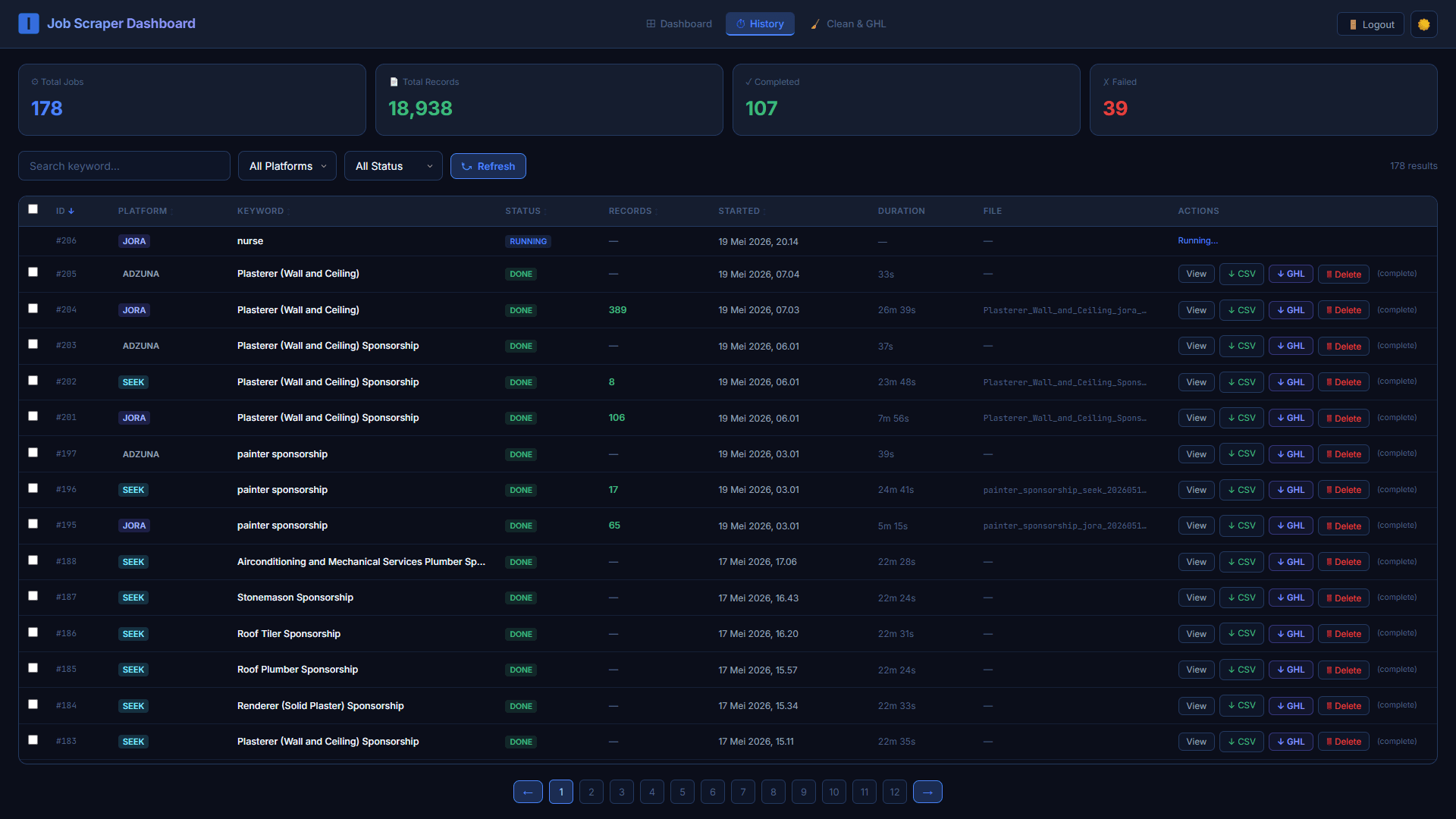
Tab History menyimpan semua scraping job yang pernah dijalankan dengan detail: platform, keyword, status (Running/Done/Failed), jumlah records, waktu mulai, durasi eksekusi, dan nama file output. Dari sini user bisa langsung View hasil, download CSV, push ke GHL, atau Delete job yang tidak diperlukan.
Dari 178 total jobs yang dijalankan, 107 selesai dengan sukses dan 39 mengalami kegagalan — angka yang jujur ditampilkan di dashboard untuk transparansi operasional.
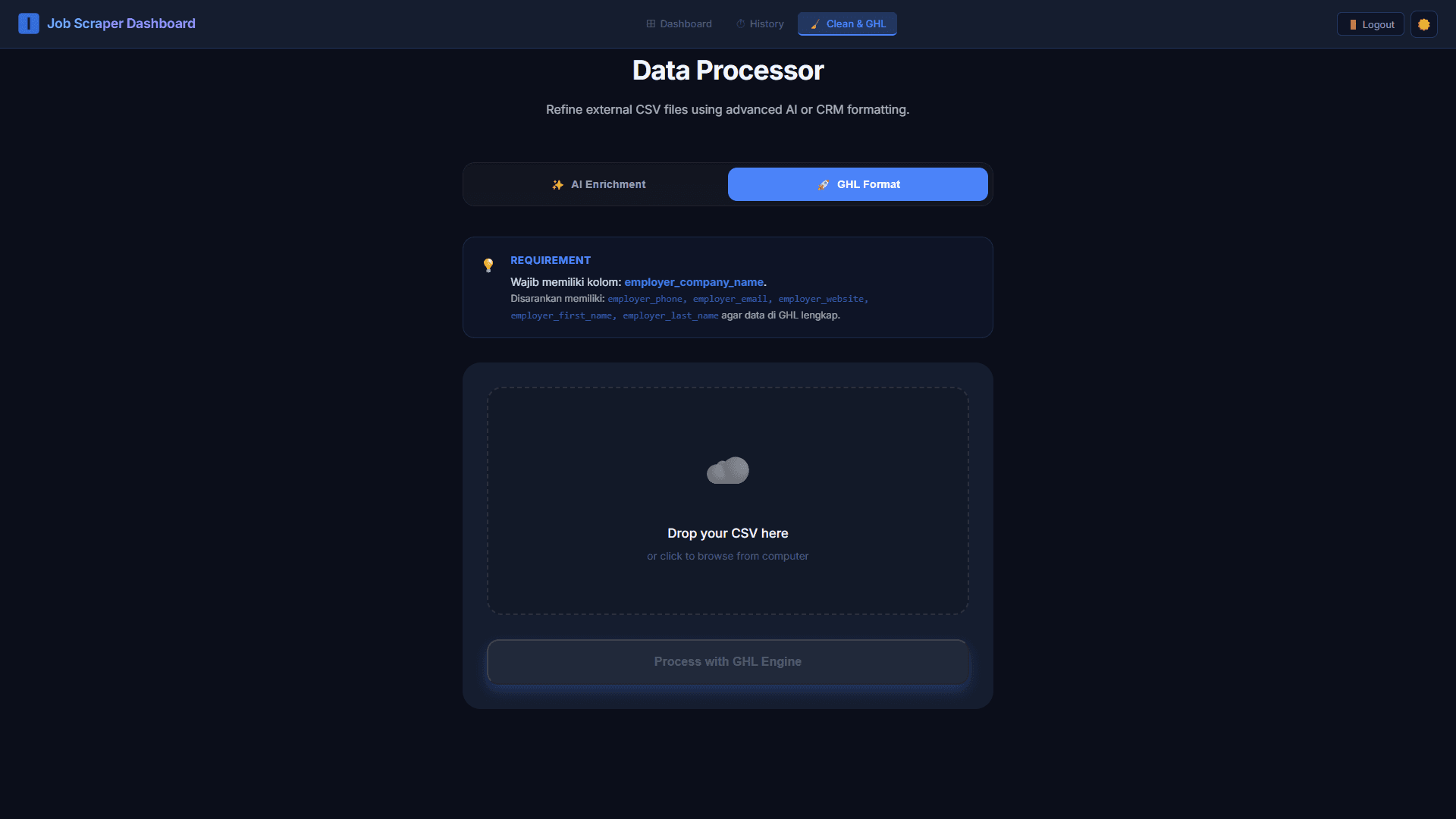
Data Processor: Clean & GHL
Setelah scraping selesai, data mentah masuk ke pipeline Data Processor yang punya dua mode:
AI Enrichment — memproses dan memperkaya data menggunakan AI, berguna untuk normalisasi nama perusahaan, ekstraksi informasi kontak dari job description, atau inferensi detail yang tidak eksplisit di listing.
GHL Format — memformat ulang CSV hasil scraping agar kolom-kolomnya sesuai dengan schema GoHighLevel. Requirement wajib adalah employer_company_name, dengan kolom tambahan yang disarankan: employer_phone, employer_email, employer_website, employer_first_name, employer_last_name.
User bisa drag-and-drop CSV eksternal ke sini — bukan hanya hasil scraping dari platform ini, tapi juga file dari sumber lain — lalu prosesnya dengan GHL Engine untuk menghasilkan file yang siap diimport sebagai contacts di GoHighLevel.
Challenge We Facing
Bot detection yang berbeda di setiap platform. Seek, Jora, Indeed, dan Adzuna masing-masing punya mekanisme anti-bot yang berbeda — rate limiting, CAPTCHA, fingerprinting browser, hingga behavioral analysis. Playwright dengan stealth mode membantu, tapi tetap butuh kalibrasi per platform: timing antar request, user agent rotation, dan penanganan saat scraper terdeteksi.
Konsistensi struktur HTML yang berubah. Job platform rutin mengupdate frontend mereka. Selector CSS atau XPath yang bekerja minggu ini bisa gagal minggu depan karena ada deployment baru di sisi platform. Ini yang sebagian besar menyebabkan 39 failed jobs — dan membutuhkan monitoring aktif serta update selector secara berkala.
Ekstraksi kontak employer yang tidak selalu eksplisit. Banyak job listing tidak mencantumkan email atau nomor telepon employer secara langsung — datanya tersebar dalam job description sebagai teks biasa, atau sama sekali tidak ada. AI Enrichment mode dibangun untuk mengisi gap ini, tapi akurasinya bergantung pada seberapa lengkap informasi yang tersedia di listing.
Normalisasi data lintas platform. Employer yang sama bisa muncul dengan nama yang sedikit berbeda di Seek vs Jora vs Adzuna (misalnya "ABC Constructions Pty Ltd" vs "ABC Constructions" vs "ABC Const."). Sebelum data bisa diimport ke GHL sebagai contacts yang bersih, deduplikasi dan normalisasi nama perlu dilakukan — proses yang tidak bisa sepenuhnya diotomasi.
Parallelism yang stabil. Menjalankan beberapa scraping job secara bersamaan tanpa race condition, tanpa overload server, dan dengan log yang tetap terbaca per job membutuhkan arsitektur queue yang dipikirkan matang — bukan sekadar fire-and-forget.
Success Metrics
Volume & coverage:
18.938 records terkumpul dari 178 scraping jobs
6 platform terintegrasi: Jora, Seek, Indeed, CareerOne, Adzuna, Workforce
Success rate 60% (107 completed dari 178 jobs) — baseline awal yang terus diimprove
Operational efficiency:
Scraping job seperti "painter sponsorship" di Jora menyelesaikan 65 records dalam 5 menit 15 detik
Data langsung tersedia dalam format CSV dan siap push ke GHL tanpa manual formatting
Tim business development bisa mulai outreach ke employer shortage dalam hari yang sama data dikumpulkan
Pipeline integration:
Output CSV dari scraper langsung kompatibel dengan GoHighLevel import format setelah melalui Data Processor
Kombinasi scraper + AI Enrichment + GHL Format menciptakan pipeline end-to-end: dari job listing publik menjadi contact yang siap di-outreach di CRM
Metrik yang terus dipantau: peningkatan success rate per platform, jumlah employer unik yang berhasil di-extract per scraping session, dan conversion rate dari scraped employer contact menjadi engaged prospect di GHL.
Gallery